几种计算机基本架构框图
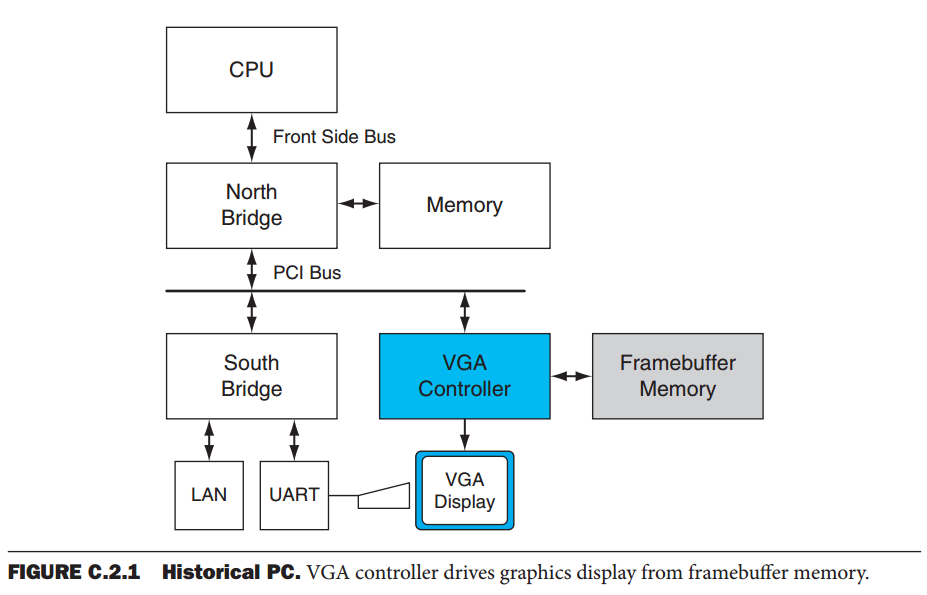
传统PC的高级框图。北桥包含高带宽接口,连接CPU,内存和PCI总线。 南桥包含传统接口和设备:ISA总线(音频,LAN),中断控制器; DMA控制器;定时/计数器。 在该系统中,显示器由称为VGA(视频图形阵列)的简单帧缓冲子系统驱动,该子系统连接到PCI总线。 1990年的PC环境中不存在具有内置处理元件(GPU)的图形子系统。
 目前常用的两种配置。 它们的特征在于独立GPU和具有相应存储器子系统的CPU。 图中,使用Intel CPU,GPU通过16通道PCI-Express 2.0链路连接,提供16 GB / s的峰值传输速率(每个方向的峰值为8 GB / s)。
目前常用的两种配置。 它们的特征在于独立GPU和具有相应存储器子系统的CPU。 图中,使用Intel CPU,GPU通过16通道PCI-Express 2.0链路连接,提供16 GB / s的峰值传输速率(每个方向的峰值为8 GB / s)。 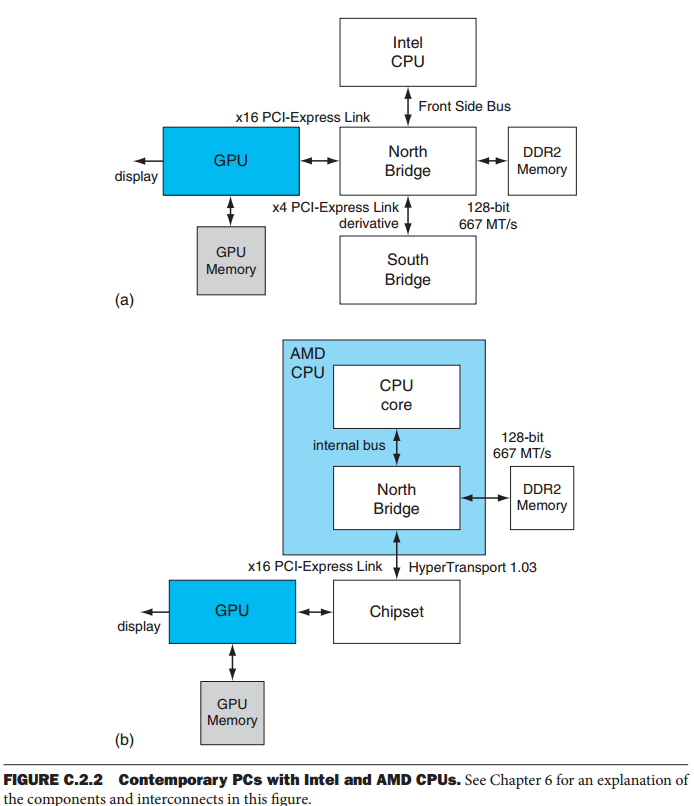 当今的GPU使用统一架构
当今的GPU使用统一架构 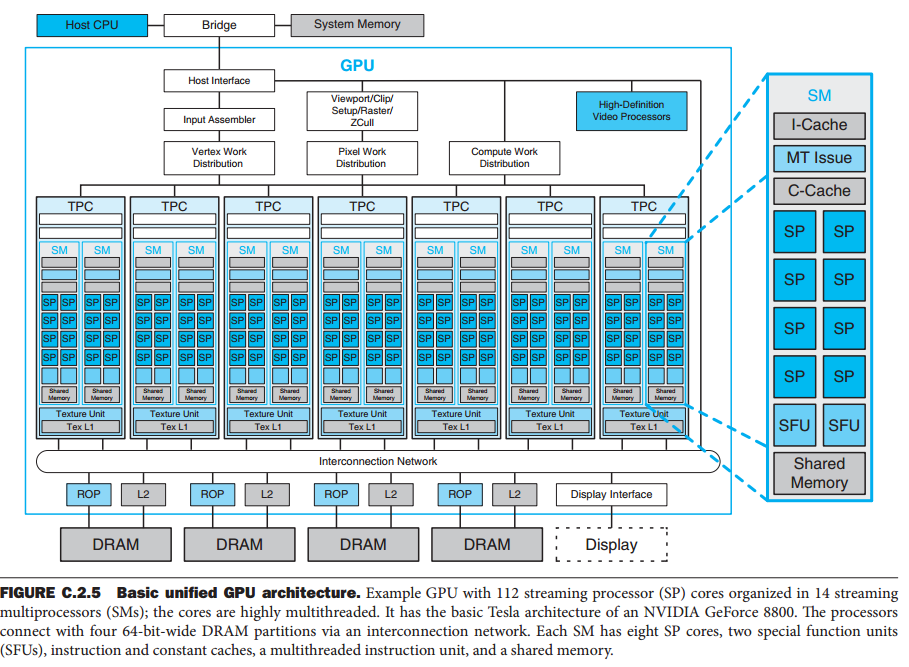 从Fermi开始NVIDIA使用一个Giga Thread Engine来管理所有正在进行的工作,GPU被划分成多个GPCs(Graphics Processing Cluster),每个GPC拥有多个SM(SMX、SMM)和一个光栅化引擎(Raster Engine),它们其中有很多的连接,最显著的是Crossbar,它可以连接GPCs和其它功能性模块(例如ROP)。
从Fermi开始NVIDIA使用一个Giga Thread Engine来管理所有正在进行的工作,GPU被划分成多个GPCs(Graphics Processing Cluster),每个GPC拥有多个SM(SMX、SMM)和一个光栅化引擎(Raster Engine),它们其中有很多的连接,最显著的是Crossbar,它可以连接GPCs和其它功能性模块(例如ROP)。
对于某些GPU(如Fermi部分型号)的单个SM,包含:
- 32个运算核心 (Core,也叫流处理器Stream Processor)
- 16个LD/ST(load/store)模块来加载和存储数据
- 4个SFU(Special function units)执行特殊数学运算(sin、cos、log等)
- 128KB寄存器(Register File)
- 64KB L1缓存
- 全局内存缓存(Uniform Cache)
- 纹理读取单元
- 纹理缓存(Texture Cache)
- PolyMorph Engine:多边形引擎负责属性装配(attribute Setup)、顶点拉取(VertexFetch)、曲面细分、栅格化(这个模块可以理解专门处理顶点相关的东西)。
- 2个Warp Schedulers:这个模块负责warp调度,一个warp由32个线程组成,warp调度器的指令通过Dispatch Units送到Core执行。
- 指令缓存(Instruction Cache)
- 内部链接网络(Interconnect Network)
在Pascal中,一个SM(流式多处理器)由128个CUDA内核组成。GP100 SM分为两个处理模块,每个模块具有32位单精度CUDA内核,一个指令缓冲区,一个warp调度程序,2个纹理映射单元和2个调度单元。使用统一内存体系结构,借助称为“页面迁移引擎”的技术,CPU和GPU可以同时访问主系统内存和图形卡上的内存。
渲染输出单元(ROP)是现代图形处理器(GPU)最后硬件组件,和在渲染过程的最后步骤之一。绘图管线取像素(每个像素是一个无量纲点),和纹理像素信息,并处理它,经由特定的矩阵和向量运算,变成最终像素或深度值。此过程称为栅格化。当多个样本合并为一个像素时,渲染输出单元控制抗锯齿。 渲染输出单元执行本地存储器中相关缓冲区之间的事务 - 这包括写入或读取值,以及将它们混合在一起。用于执行基于硬件的抗锯齿方法(如多重采样抗锯齿(MSAA))的专用抗锯齿硬件包含在渲染输出单元中。渲染的所有数据都必须通过渲染输出单元才能写入帧缓冲器,帧缓冲器再传输到VGA、DVI、HDMI、Displayport、 Mini Displayport线到显示器。历史上,渲染输出单元,纹理映射单元和着色器处理单元/ 流处理器的数量是相等的。然而,从2004年开始,几个GPU已经将这些区域分离,以便为应用程序工作负载和可用内存性能提供最佳的晶体管分配。随着趋势的继续,预计图形处理器将继续解耦其架构的各个部分,以增强其对未来图形应用程序的适应性。这种设计还允许芯片制造商构建模块化阵容,其中顶级GPU基本上使用与低端产品相同的逻辑。
8750H和CM246芯片组
coffee lake架构框图
x1e的i7-8750H和CM246芯片组,都基于coffee lake架构,架构框图如下: 该芯片组PCH 上有多达 30 个高速 I/O 通道,详细图如下:
概览图如下:
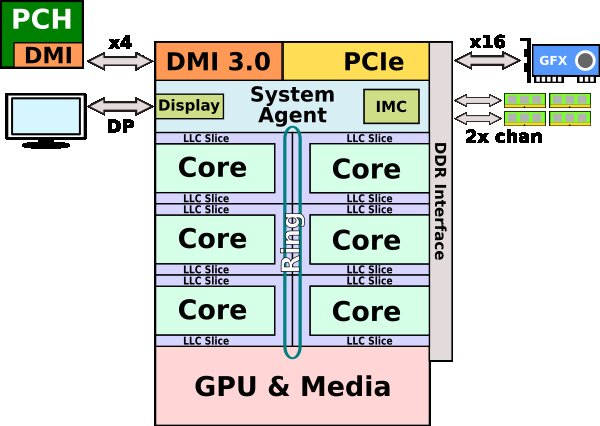
coffee lake系统芯片组成
Coffee Lake系统芯片由五个主要组件组成:CPU ,LLC,环形互连,系统代理和集成显卡。自2011年推出Sandy Bridge以来,Coffee Lake是英特尔主流微体系结构的最大变化。2006年,英特尔推出了第一款主流四核处理器Core 2 Extreme QX6700,该处理器基于Kentsfield核心。 这些四核处理器由两个独立的管芯组成,这些管芯在多芯片封装中互连。前端总线用作芯片到芯片(die-to-die)的链接,后来到Penryn平台这种配置并没有改变,直到2008年推出基于Nehalem微体系结构的Core i7,Nehalem将所有四个内核整合到一个芯片上并进行大量更改,特别是增强uncore(现在称为系统代理)。 Core i7-980X也是第一款六核用户芯片。 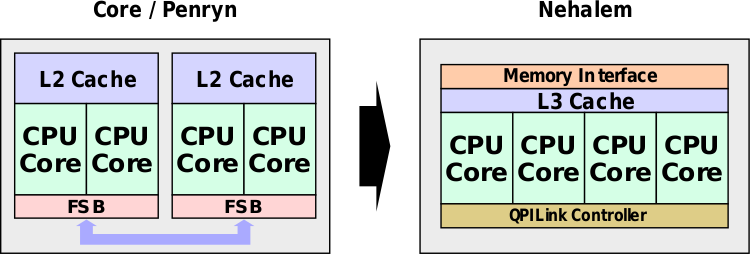 SoC整体概览(hexa):
SoC整体概览(hexa): 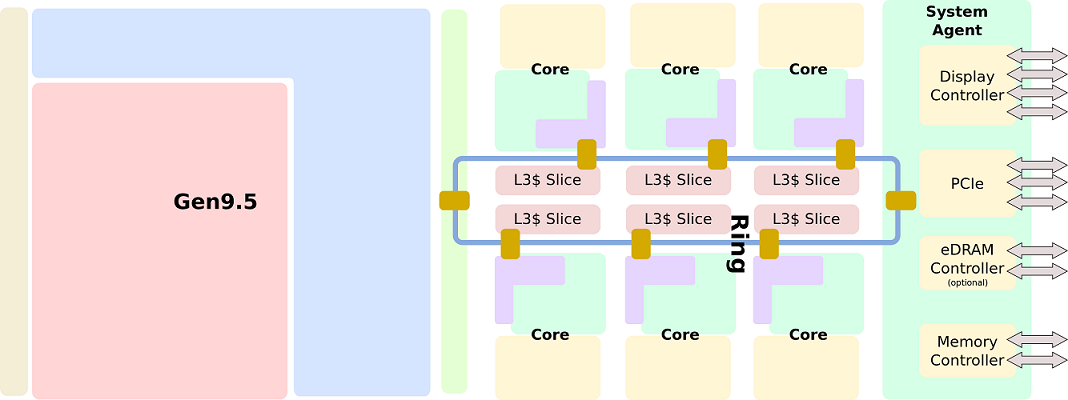 单核框图:
单核框图:  随着2011年Sandy Bridge的推出,整个系统架构进行了重新设计。 Sandy Bridge的一个特殊目标是其可配置性。 英特尔希望能够在多个细分市场中使用单一设计,而无需在多个物理设计上花费额外资源。其模块化的很大一部分来自Sandy Bridge实现的环形互连(Last Level Cache)。 该环允许英特尔在Sandy Bridge中集成System Agent和集成显卡。
随着2011年Sandy Bridge的推出,整个系统架构进行了重新设计。 Sandy Bridge的一个特殊目标是其可配置性。 英特尔希望能够在多个细分市场中使用单一设计,而无需在多个物理设计上花费额外资源。其模块化的很大一部分来自Sandy Bridge实现的环形互连(Last Level Cache)。 该环允许英特尔在Sandy Bridge中集成System Agent和集成显卡。 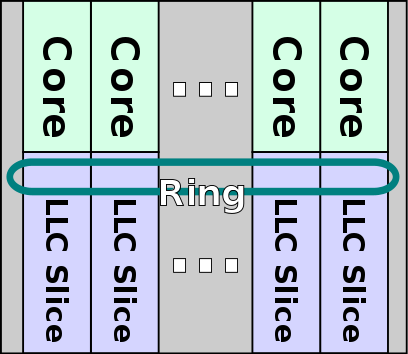 这些组件中的每一个都有自己的环代理(除了单个核心),允许在GPU,SA以及各个核心和高速缓存之间有效地传输数据。 最终结果是一个完整的片上系统(SoC)在单个裸片上有四个内核和一个12 EU GPU。
这些组件中的每一个都有自己的环代理(除了单个核心),允许在GPU,SA以及各个核心和高速缓存之间有效地传输数据。 最终结果是一个完整的片上系统(SoC)在单个裸片上有四个内核和一个12 EU GPU。
由于Coffee Lake采用了英特尔第三代增强型14nm成熟工艺,因此英特尔可以将核心数量从4核增加到6核。 现有的环形互连专门设计用于支持此配置。 除了两个添加的核心之外,还有两个额外的LLC切片。 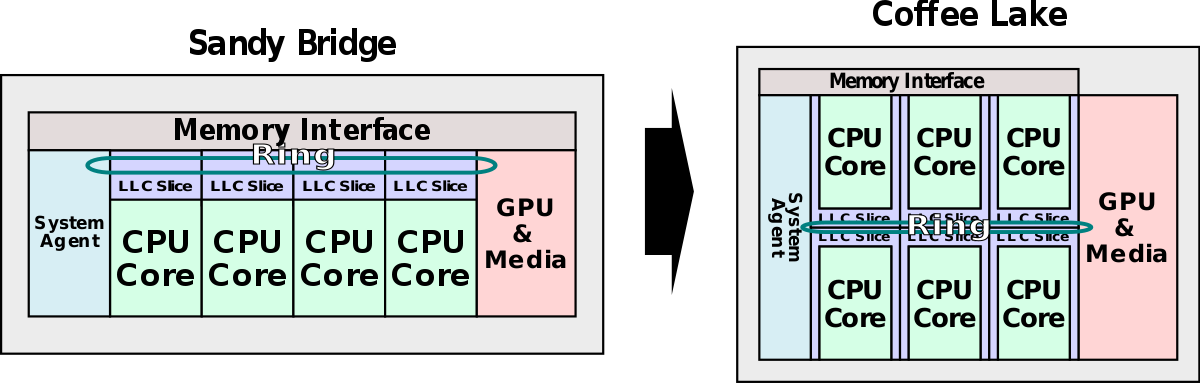 coffee lake环示意图:
coffee lake环示意图: 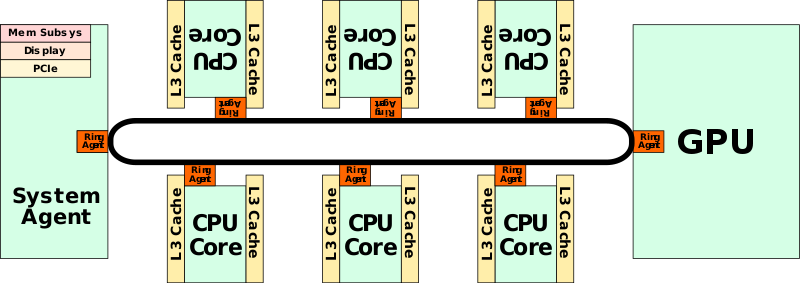 新的十一代cpu架构:
新的十一代cpu架构: ps:工艺制造中lot指按某种方式生成的硅柱状体,将这些lot切成薄片就称为wafer,wafer是进行集成电路制造的基板,一般以直径来区分,8寸、10寸,12寸等,或者以毫米来区分。直径越大材料的利用率越高,因为在wafer的周边由于弧形的关系是没法利用的 。在wafer上根据需要划分不同的区域,每个区域用于生产特定功能的芯片,称之为die。总的来说,Die或CPU Die指的是处理器在生产过程中,从晶圆(Silicon Wafer)上切割下来的一个个小方块(常见CPU芯片都是方形),在切割下来之前,每个小方块(Die)都需要经过各种加工,将电路逻辑刻到该Die上面。die-to-die即芯片对芯片。
 对于主流的CPU厂商Intel和AMD而言,他们会将1个或者N个CPU Die封装起来形成一个CPU Package,有时候也叫作CPU Socket。
对于主流的CPU厂商Intel和AMD而言,他们会将1个或者N个CPU Die封装起来形成一个CPU Package,有时候也叫作CPU Socket。
总线
总线是在计算机部件之间或计算机之间传输数据的子系统。 类型包括:
- 前端总线(FSB) 它在CPU和内存控制器之间传输数据。
- 直接媒体接口(DMI) 它是英特尔集成内存控制器和计算机主板上的英特尔I/O控制器中心之间的点对点互连;用于主板上南桥芯片和北桥芯片之间的连接。DMI与PCIe总线共享了大量的技术特性,像是多通道、差分信号、点对点连线、全双工、8b/10b编码等。大部分DMI的通信布局类似于PCIe x4规格。DMI 3.0于2015年8月发布,每通道可拥有最大8GT/s的吞吐量(8750H的总线速度,也就是说x1e支持DMI3.0的总线接口,其前端总线接口为BCLK),x4规格时有3.93GB/s的带宽。也用于CPU与PCH的连接。
- 快速通道互连(QPI) 它是CPU和集成内存控制器(IMC)之间的点对点互连。
在传统架构中,前端总线充当CPU与系统中所有其他设备(包括主存储器)之间的直接数据链路。在基于HyperTransport和QPI的系统中,系统存储器通过集成在CPU 中的内存控制器独立访问,留下HyperTransport或QPI链路上的带宽用于其他用途。这增加了CPU设计的复杂性,但在多处理器系统中提供了更高的吞吐量和出色的扩展性。Core i7-8750H就使用的IMC,如下所示 |属性|参数| |----|----| |最大类型|DDR4-2666,LPDDR3-2133| |支持ECC|否| |最大内存|64 GiB| |控制器|1| |通道|2| |宽度|64位| |最大带宽|(39.74GiB/s?)41.8GB/s| |带宽|单通道:19.87GiB/s;双通道:39.74GiB/s| 其中最大带宽是处理器可以从半导体存储器读取数据或将数据存储到半导体存储器中的最大速率(以GB/s为单位)。 - PCI-E Peripheral Component Interconnect Express(或PCIe)是一种高速串行计算机扩展总线标准,用于将硬件设备连接到计算机。不同的PCI Express版本支持不同的数据速率。 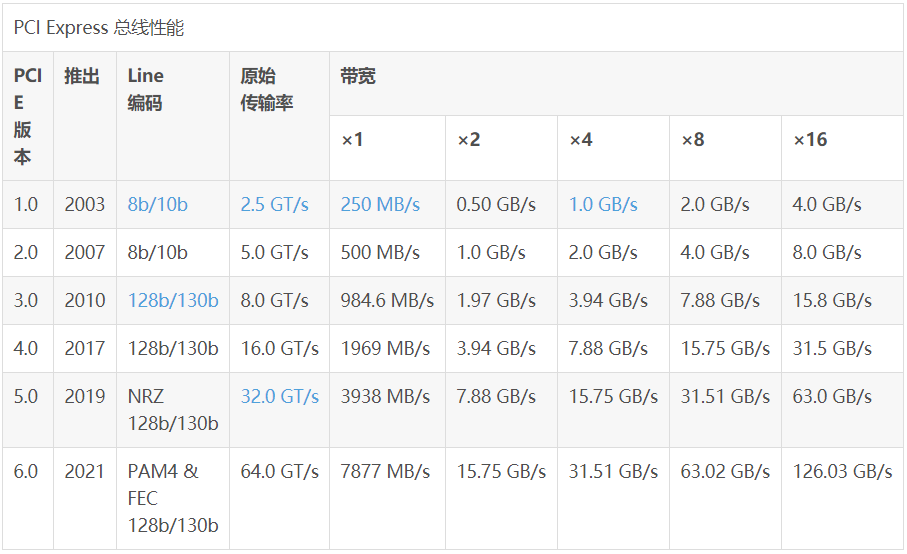 我们看到X1,X2,X4…是指PCIe连接的通道数(Lane)。
我们看到X1,X2,X4…是指PCIe连接的通道数(Lane)。
PCI-E串行总线带宽(MB/s) = 串行总线时钟频率(MHz)x串行总线位宽(bit/8 = B)x 串行总线管线x 编码方式x 每时钟传输几组数据(cycle),例:双工PCI-E 1.0 X1,其带宽 = 2500x1/8x1x8/10x1x2=500 MB/s。
两个设备之间的PCIe连接,叫做一个Link,如下图所示: PCI-e是全双工,发送和接收可以同时进行,而且没有时钟线,它是采用8/10和128/130的编码方式把时钟编入传输信号内的。PCI-e3.0可是工作在4Ghz的频率上。PCIe链路使用串行方式进行数据传送,然而在芯片内部,数据总线仍然是并行的,因此PCIe链路接口需要进行串并转换,这种串并转换将产生较大的延时。除此之外PCIe总线的数据报文需要经过事务层、数据链路层和物理层,这些数据报文在穿越这些层次时,也将带来延时。在4Ghz的频率下,任何一点延时都会带来问题。
两个PCIe设备之间,有专门的发送和接收通道,数据可以同时往两个方向传输,PCIe spec称这种工作模式为双单工模式(dual-simplex)。前面PCIe带宽那张表,上面的带宽,比如PCIe3.0x1,带宽为2GB/s,是指双向带宽,即读写带宽。如果单指读或者写,该值应该减半,即1GB/s的读速度或者写速度。
传输速率为每秒传输量GT/s,而不是每秒位数Gbps,因为传输量包括不提供额外吞吐量的开销位; 比如 PCIe 1.x和PCIe 2.x使用8b / 10b编码方案,导致占用了20% (= 2/10)的原始信道带宽。
GT/s —— Giga transation per second (千兆传输/秒),即每一秒内传输的次数。重点在于描述物理层通信协议的速率属性,可以不和链路宽度等关联。GT/s 与Gbps 之间不存在成比例的换算关系。
PCIe 吞吐量(可用带宽)计算方法:
吞吐量 = 传输速率 * 编码方案
例如:PCI-e2.0 协议支持 5.0 GT/s,即每一条Lane 上支持每秒钟内传输 5G个Bit;但这并不意味着 PCIe 2.0协议的每一条Lane支持 5Gbps 的速率。因为PCIe 2.0 的物理层协议中使用的是 8b/10b 的编码方案。 即每传输8个Bit,需要发送10个Bit。
那么, PCIe 2.0协议的每一条Lane支持 5 * 8 / 10 = 4 Gbps = 500 MB/s 的速率。
以一个PCIe 2.0 x8的通道为例,x8的可用带宽为 4 * 8 = 32 Gbps = 4 GB/s。 经检测,x1e使用的m.2280的nvme接口为PCI-E 2.0x4,速率2GB/s,另外雷电3的桥接也使用该规格。而北桥除了内存控制器之外,还有1050Ti显卡使用了PCI-E 2.0x16的控制器,速率8GB/s。
计算机内存
计算机内存历史
内存有多种形式,但是在非易失性内存(NVM)出现之前,计算世界首先以随机存取内存(RAM)的形式引入易失性内存。RAM引入了在相同的时间内向/从存储介质的任何位置写入/读取数据的功能。特定数据集通常是随机的物理位置,并不影响操作完成的速度。通过缓存经常读取的数据或暂存需要写入的数据,这种类型的内存的使用掩盖了从指数级较慢的HDD访问数据的痛苦。
RAM技术中最著名的是动态随机存取存储器(DRAM)。硬盘驱动器十年后的1966年,它也从IBM实验室出来。DRAM与CPU距离更近,并且也不必处理机械组件(即HDD),因此其运行速度非常快。即使在今天,许多数据存储技术都在努力以DRAM的速度运行。但是这有一个缺点:一旦电容器驱动的集成电路(IC)断电,数据就会随之消失。
DRAM技术的另一缺点是其容量非常低,每GB的价格也很高。即使按照今天的标准,与较慢的HDD和SSD相比,DRAM还是太昂贵了。
DRAM首次亮相后不久,便出现了可擦可编程只读存储器(EPROM)。它是由英特尔发明的,于1971年左右问世。与易失性同类产品不同,EPROM内存在系统电源关闭后立即保留其数据。EPROM在其IC中使用晶体管代替电容器。这些晶体管即使在断电后也能够保持状态。 顾名思义,EPROM属于其自己的只读存储器(ROM)类。通常,数据是使用特殊的设备或工具预先编程到这些芯片中的,而在生产时,它的目的是唯一的:从高速读取数据。这种设计的结果是,EPROM立即在嵌入式和BIOS应用程序中变得很流行,后者则存储了特定于供应商的详细信息和配置。
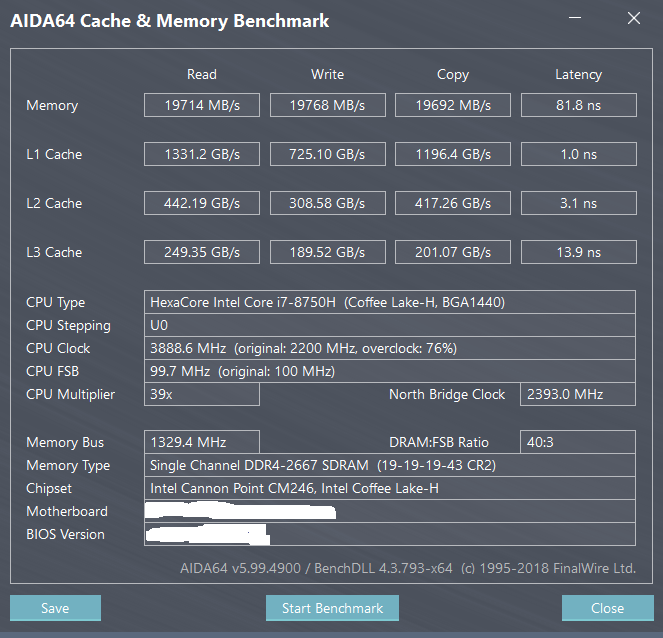
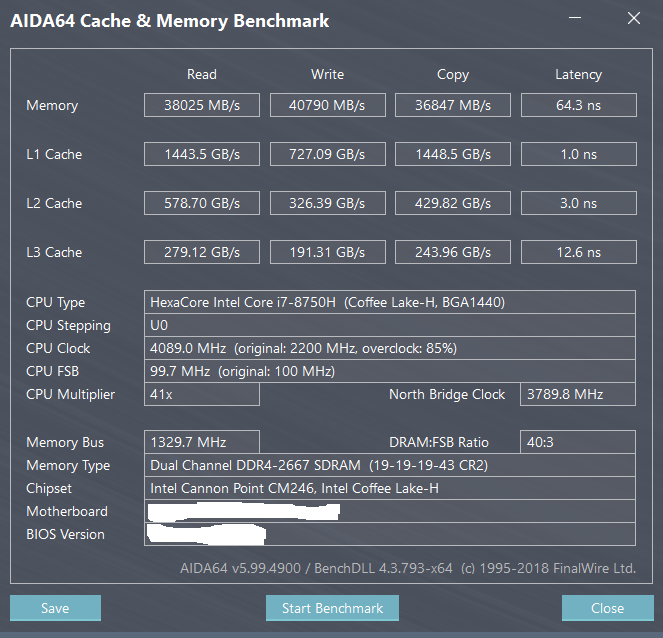
i7-8750H内存带宽
4GHz频率的i7-8750H中的集成内存控制器IMC上的16GB2双通道DDR4-2666总内存带宽约为40GB/s,如图所示。
- 单通道
- 双通道
GPU显存特点
一是GPU的显存带宽较大。理论上常见GPU使用的16通道PCIe 2.0接口的峰值带宽约8GB/s,像GeForce GTX1080 Ti显卡的显存带宽接近500GB/s。二是GPU的显存访问延迟较大。GPU是为高吞吐量而非低延迟构建的,因此从缓存延迟到全局内存延迟往往比CPU更高。在i7-8750H上主内存没有命中缓存的情况,大约需要4GHz64ns=256个时钟周期来获取数据。PCIe接口的GPU全局内存没有命中缓存的情况,需要延迟大约400以上的时钟周期。
NVMe
HDD
IBM于1956年首次亮相HDD。到1960年代,HDD成为通用计算机中占主导地位的辅助存储设备。容量和性能是定义HDD的主要特征。
IBM制造的第一个硬盘驱动器350 RAMAC与两个中型冰箱一样大,在50个磁盘的堆栈上总容量为3.75MB。现代HDD技术已生产出容量高达16TB的磁盘驱动器,特别是结合了SMR技术和氦气。密封的氦气增加了驱动器的潜在速度,同时减少了阻力和湍流。由于密度不如空气,因此还可以在2.5英寸和3.5英寸常规磁盘驱动器使用的相同空间中堆叠更多的磁盘。
磁盘驱动器的性能通常由将驱动器磁头移动到特定磁道或圆柱体所需的时间以及请求的扇区在磁头下移动所需的时间(即延迟)来计算。还以传输数据的速率来衡量性能。
作为机械设备,HDD的不如内存快。许多移动组件增加了等待时间,并降低了访问数据的整体速度(用于读取和写入操作)。
每个HDD的内部都有磁性磁盘,通常称为磁盘。这些拼盘是存储信息的地方。HDD由一根主轴绑定并一致地旋转,一个HDD将有一个以上的盘片并排放置,它们之间的空间最小。
与留声机唱片的工作原理类似,唱片是双面的,每个唱片的表面都有圆形的蚀刻,称为轨道。每个轨道由扇区组成。随着靠近盘片边缘,每个轨道上的扇区数都会增加。如今,您会发现一个扇区的物理大小为512字节或4千字节(4096字节)。在编程中,扇区通常等同于磁盘块。
磁盘旋转的速度会影响信息的读取速度。这定义为磁盘的旋转速率,以每分钟转数(RPM)进行测量。这就是为什么现代驱动器以7200 RPM(或每秒120转)的速度运行的原因。较旧的驱动器以较低的速度旋转。高端驱动器可能以更高的速度旋转。此限制造成了瓶颈。
执行器臂位于盘片上方或下方。它在其表面上延伸和缩回。手臂末端是一个读写头。它位于盘子表面上方的微观距离处。随着磁盘旋转,磁头可以访问当前磁道上的信息(不移动)。但是,如果磁头需要移动到下一个轨道或完全不同的轨道,则会增加读取或写入数据的时间。从程序员的角度来看,这称为磁盘搜索,这造成了第二个瓶颈。 现在,尽管通过更新的磁盘访问协议(例如串行ATA(SATA)和串行连接的SCSI(SAS))和技术,HDD的性能一直在提高,但它仍然是CPU以及整个计算机系统的瓶颈。每个磁盘协议对最大吞吐量(每秒兆字节或千兆字节)都有自己的硬性限制。数据传输的方法也非常串行化。这在旋转的磁盘上很好用,但不能很好地扩展到Flash技术。
SSD
近年来,固态硬盘(SSD)的市场份额持续攀升,取代了许多行业的HDD。当第一批商用SSD进入市场时,公司和个人都很快就采用了该技术。即使价格更高,与HDD相比,人们还是能够证明其合理性。时间就是金钱,如果访问驱动器可以节省时间,则可能会增加利润。但不幸的是,随着第一个基于NAND的商业化SSD的推出,该驱动器并没有将数据存储移到更靠近CPU的地方。这是因为早期的供应商选择采用现有的磁盘接口协议,例如SATA和SAS。该决定的确鼓励了消费者的采用,但同样它限制了整体吞吐量。
尽管SSD并没有靠近CPU,但它的确实现了该技术的新里程碑-减少了跨存储介质的寻道时间,从而大大减少了延迟。这是因为驱动器是围绕IC设计的,并且不包含可移动组件。SSD不会将数据保存到旋转磁盘上,而是将相同的数据保存到NAND闪存池中。NAND技术与DRAM中使用的晶体管设计(必须每秒刷新多次)不同,NAND即使在没有电源的情况下也能够保持其充电状态,因此是非易失性的。
M-Systems于1995年推出了第一款无需电源(即电池)即可维持状态的正式SSD。它们旨在替代军事和航空航天应用关键任务中的HDD。到1999年,以传统的3.5英寸存储驱动器外形设计并提供了基于闪存的技术,并且一直以这种方式进行开发,直到2007年新成立的革命性初创公司Fusion-io(现已成为Western Digital的一部分)决定改变传统存储驱动器的性能极限形式,并将该技术直接应用于PCI Express(PCIe)总线,这种方法消除了许多不必要的通信协议和子系统,设计也离CPU越来越近,并产生了明显的性能改进。
后来,Fusion-io的产品启发了其他内存和存储公司,将一些类似的技术引入了双列直插式内存模块(DIMM)尺寸,该尺寸可直接插入支持的主板的传统RAM插槽中。这些类型的模块作为不同的内存类别注册到CPU,并保持某种程度的保护模式。除非通过专门设计的设备驱动程序或应用程序接口完成操作,否则主系统以及相应的操作系统都不会接触这些存储设备。
在这里还值得注意的是,与DRAM性能相比,基于晶体管的NAND闪存技术仍然显得苍白。我说的是微秒延迟与DRAM的纳秒延迟。即使采用DIMM尺寸,基于NAND的模块的性能也不如DRAM模块好。
靠近CPU
显而易见,将数据(存储)移到CPU越近,访问(和操作)数据的速度就越快。最接近CPU的内存是处理器的寄存器。处理器可用的寄存器数量因体系结构而异。该寄存器的目的是保存少量打算用于快速存储的数据。毫无疑问,这些寄存器是访问小尺寸数据的最快方法。
接下来,紧随CPU的寄存器的是CPU缓存。这是内置在处理器模块中的硬件高速缓存,CPU可以利用它来减少从主存储器(DRAM)访问数据的成本和时间。它是围绕静态随机存取存储器(SRAM)技术设计的,该技术也是一种易失性存储器。像典型的高速缓存一样,此CPU高速缓存的目的是存储来自最频繁使用的主内存位置的数据副本。在现代CPU架构上,存在多个不同的独立缓存(并且其中一些缓存甚至被拆分了)。它们按照缓存级别的层次结构进行组织:级别1(L1),级别2(L2),级别3(L3),依此类推。处理器越大,缓存级别越多,级别越高,它可以存储的内存就越多(即从KB到MB),其位置离主CPU越远,但它也确实引入了延迟。
首次使用处理器中的高速缓存的记录可以追溯到1969年,然后是IBM System/360 Model 85大型机。直到1980年代,更主流的微处理器才开始合并自己的CPU缓存。部分原因是成本。就像今天一样,(所有类型的)RAM非常昂贵。 因此,数据访问模型是这样的:离CPU越远,延迟就越大。DRAM的位置比HDD位置更靠近CPU,但不及IC中设计的寄存器或高速缓存级别那么近。
非易失性内存Express(NVMe)
NVMe(非易失性内存Express,或称非易失性内存主机控制器接口规范)是一种用于访问高速存储介质的新协议,该协议是相对较新的,功能丰富的协议,它是专为通过PCIe接口直接连接到CPU的非易失性存储介质(NAND和持久性存储器)而设计的。该协议建立在高速PCIe通道上。PCIe Gen 3.0链接可提供的传输速度是SATA接口的两倍以上。 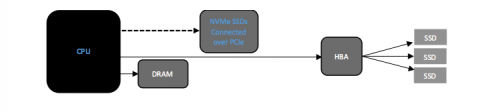 NVMe协议利用到底层介质的并行,低延迟数据路径,类似于高性能处理器体系结构。与传统的SAS和SATA协议相比,这提供了显着更高的性能和更低的延迟。
NVMe协议利用到底层介质的并行,低延迟数据路径,类似于高性能处理器体系结构。与传统的SAS和SATA协议相比,这提供了显着更高的性能和更低的延迟。
Fusion-io构建了封闭的专有产品。仅这一事实就吸引了许多行业领导者共同定义新标准,以与先驱竞争,并将更多的PCIe连接的闪存推入数据中心。拥有行业第一规范NVMe在2011年宣布推出后,迅速上升到SSD技术的最前沿。请记住,从历史上看,SSD是基于SATA和SAS总线构建的。这些接口对于成熟的闪存技术工作得很好,但是在所有协议开销和总线速度限制的情况下,这些驱动器很快就经历自己的合理性能瓶颈(和限制)。如今,现代SAS驱动器以12Gbit / s的速度运行,而现代SATA驱动器以6Gbit / s的速度运行。这就是为什么该技术将重点转移到PCIe的原因。随着总线距离CPU越来越近,PCIe能够以越来越高的速度运行,SSD似乎正好适合。使用PCIe 3.0,现代驱动器可以达到40Gbit / s的速度。对NVMe驱动器的支持已集成到Linux 3.3主线内核(2012年)中。
NVMe真正使操作系统的旧式存储堆栈大放异彩的原因在于其更简单,更快速的排队机制。这些称为提交队列(SQ)和完成队列(CQ)。每个队列都是固定大小的循环缓冲区,操作系统使用该缓冲区将一个或多个命令提交给NVMe控制器。这些队列中的一个或多个也可以固定到特定的内核,这样可以进行更多不间断的操作。再见串行通讯。现在驱动器I/O已并行化。
NVMeoF
在SAS或SATA的世界中,有存储区域网络(SAN)。SAN是根据SCSI标准设计的。SAN(或任何其他存储网络)的主要目标是通过一条或多条路径提供对一个或多个存储卷的访问,以访问网络中的一个或多个操作系统主机。如今,最常用的SAN基于iSCSI,即基于TCP / IP的SCSI。从技术上讲,NVMe驱动器可以在SAN环境中进行配置,尽管协议开销会引入延迟,这使其成为不太理想的实现方式。2014年,NVMe Express委员会准备采用NVMeoF标准进行纠正。
NVMeoF的目标很简单:启用围绕NVMe排队体系结构构建的NVMe传输桥,并避免支持的NVMe命令(端到端)以外的任何协议转换开销。通过这种设计,网络等待时间会明显下降(小于200ns)。此设计依赖于PCIe交换机的使用。基于使用远程直接内存访问(RDMA)的现有以太网结构的第二种设计正在取得进展。
Linux内核引入了许多支持NVMeoF的新代码。这些补丁是英特尔,三星和其他地方的辛勤工作的开发人员共同努力的一部分。内核中修补了三个主要组件,包括常规的NVMe Target Support框架。该框架使模块设备可以使用NVMe协议从Linux内核中导出。依赖于此框架,现在支持NVMe环回设备以及基于Fabrics RDMA目标的NVMe。如果您还记得的话,这最后一部分是另外两个常见的NVMeoF部署之一。